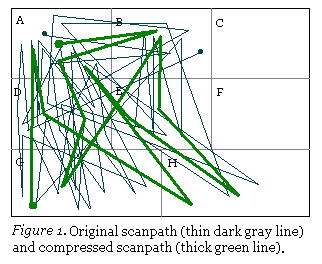
A scanpath is a sequence of fixations and saccadic eye movements during image viewing. Naturally, characteristics of scanpaths should reflect characteristics of underlying cognitive processes, and the similarities and differences between two scanpaths can be used to infer the similarities and differences of cognitive processes taken place during viewing experimental stimuli.
Brandt and Stark (1997) adopted the string-editing algorithm to compare the similarity between two scanpaths. Suppose the viewing area can be divided into a finite amount of regions. We can assign each region a single-letter name, while the same letter is used for labeling at most one region. Consequently, the scanpaths, or fixation sequences, can be represented as letter strings. The string-editing algorithm computes the minimum editing cost to transform one letter string into another. The cost can then be normalized by dividing by the length of the analyzed strings to get the relative distance as a measure for similarity between eye movement patterns.
Before string-editing analysis can be performed, however, the two scanpaths need to be compressed by removing duplicate fixations with respect to locations and sequences. For example, suppose we have the following string (from Brandt & Stark, 1997, Figure 4):
ABCEDEFGABCDEFGG
By removing consecutive, duplicate fixations at the same location we get:
ABCEDEFGABCDEFG
The sequence "ABC" and "DEF" both occur twice, so the second occurrences are removed. Here is the resulted string:
ABCEDEFGG
Now, remove the duplicate G, we get:
ABCEDEFG
Therefore, the compressed scanpath can be viewed as a compact representation of the characteristics of the raw scanpath.
I have written a program to compress scanpaths according to the algorithm described above. The program was originally written to help a colleague of mine who was working on string-editing analysis but did not have a suitable scanpath compression tool.
The program uses an aggressive, recursive compression algorithm. It first removes duplicate fixations at the same location. Then it removes duplicate sequences. The resulted string is then submitted to the same process recursively, until nothing can be removed. Here is an example:
ABADGDADADGDADGDGDGBEBEBEHBAEDGAHDABDAGDADAGDGDADB
ABADGDADadgdadGDGDGBEBEBEHBAEDGAHDABDAGDADAGDGDADB
ABADGDADGDGDGBEBEBEHBAEDGAHDABDAGDADAGdgdadB
ABADGDadgdGDGBEBEBEHBAEDGAHDABDAGDADAGB
ABADGDGDGBEBEBEHBAEDGAHDABDAGDAdagB
ABADGDGDGBEBEBEHBAEDGAHDABDAGdab
ABADGDGDGBEBEBEHBAEDGAHDabDAG
ABADGDGDGBEBEBEHbaEDGAHDAG
ABADGdgdgBEBEBEHEdgAHDAG
ABADGBEbebeHEAHDAG
ABADGBEHEAHDAG
The program can handle at most 26 different regions, which should be sufficient for most image-viewing studies. The input should be organized with one scanpath per line. Within each line, fixations should be represented by their corresponding region numbers (ranged from 1 to 26 inclusive), not letters. A space should be inserted between two consecutive fixations.
The output will be letter strings, with "A" representing region "1", "B" representing "2", and so on.
The program is written in ANSI C, so one should have no problem compiling it with most C/C++ compilers. However, due to its recursive nature, you may need to increase the default stack size during compilation to reduce the risk of stack overflow.
Copyright (c) 1999-2001 Chih-Hao Tsai.
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
The program (Win32 console program), source code, and sample input and output can be downloaded by clicking on the following link:
Download: scanpath.zip
Brendt, S. A., & Stark, L. W. (1997). Spontaneous eye movements during visual imagery reflect the content of the visual scene. Journal of Cognitive Neuroscience, 9(1), 27-38.