Back-propagation is the most widely used supervised learning algorithm for artificial neural networks. A typical back-propagation network consists of three fully connected layers: input, hidden, and output, with each processing unit connected to every unit in the layers above and below. I assume you are already familiar with the back-propagation algorithm, and therefore I will not go into further details of it. If you are not familiar with back-propagation (or neural networks in general), Chapter 19 of Russell and Norvig's (1995) artificial intelligence textbook provides a brief but excellent introduction. You may also want to read Rumelhart, Hinton, and Williams (1986), which is one of the chapters in the famous book Parallel Distributed Processing (Rumelhart & McClelland, 1986) that popularized back-propagation in artificial intelligence, cognitive science, as well as many other fields.
IML-BKP is an implementation of the standard back-propagation network in SAS/IML (interactive matrix language). All other programs I have made available on the web were written in C. IML-BKP was original written in 1995 to process a huge set of data. I was using SAS to perform statistical analyses on the set of data. Instead of writing a separate C program, I decided to implement the network in IML so I could run it within SAS.
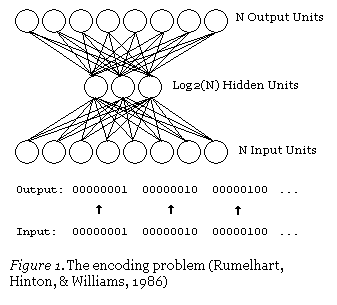
The program is very small, very straightforward, and commented. If you are familiar with SAS/IML (and back-propagation) you should have no difficulty understanding it. I have also implemented the Encoding problem as described in Rumelhart, Hinton, and Williams (1986; pp. 335-339) as a sample problem for IML-BKP. In an encoding problem a set of orthogonal input patterns to a set of orthogonal output patterns through a small set of hidden units. As a result, the hidden units must be very flexible and efficient to ensure successful learning.
Copyright (c) 1995-2001 Chih-Hao Tsai.
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
Download: iml-bkp.zip
Rumelhart, D. E., & McClelland, J. L. (Eds.). (1986). Parallel distributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations. Cambridge, MA: MIT.
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning internal representations by error propagation. In D. E. Rumelhart & J. L. McClelland (Eds.), Parallel distributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations (pp. 318-364). Cambridge, MA: MIT.
Russell, S., & Norvig, P. (1995). Artificial intelligence: A modern approach. Upper Saddle River, NJ: Prentice-Hall.